
AI Forgery: How Artificial Intelligence Uncovers Fake PDFs
Why PDF forgery is accelerating in a digital-first economy
PDF fraud is growing for a simple reason: the business world now runs on remote, document-based decisions. Customer onboarding, supplier approval, employment checks, loan underwriting, insurance claims, and expense reimbursement increasingly start (and often finish) with “upload a PDF.” Regulators and supervisors have explicitly treated remote onboarding as a risk area that must be governed, tested, and monitored—because it expands the opportunity surface for impersonation and fraud at scale. The reliance on outdated, document-centric KYC processes, such as scanning a driver's license or passport, is a systemic vulnerability affecting numerous sectors.
At the same time, the marginal cost of producing convincing fakes keeps falling. Recent threat assessments warn that generative AI systems—especially large language models and image-generation tools—are reducing the barrier to entry for digital crime, enabling highly realistic synthetic media, and making impersonation more effective. The FBI warns that criminals exploit generative AI to commit fraud on a larger scale, increasing the believability of their schemes. That means fewer skilled specialists are needed to generate “good enough” or even “excellent” forgeries.
Real-world fraud intelligence mirrors that shift. Cifas reported that false applications rose in 2024, with false documentation the most common filing reason, particularly across banking and insurance; it also explicitly notes increasing sophistication and volume of false documentation, and that organizations are seeing the same templates circulating with simple edits. In parallel, ICAEW has described how accessible generative AI is being used to produce fake documentation—including payslips, invoices, and bank statements—so realistic that it can be difficult to detect through standard checks. This has led to a surge in AI scams, with common types including the use of AI to create fake documents, deepfakes, and voice clones to deceive victims and commit fraud.
The result is a new baseline: “looks authentic” no longer equals “is authentic.” The difference increasingly sits inside the file—within the PDF’s structure, object graph, metadata, and rendering logic—where humans rarely look and manual processes cannot consistently scale.
Why humans struggle to detect fake PDFs
Modern document forgeries are designed to pass surface scrutiny. Typography can be cloned, logos can be replicated pixel-perfectly, and layouts can be copied from real templates with minimal variation. That is precisely why fraud teams are seeing template reuse with simple edits to personal details and transactions: it exploits the fact that reviewers are trained (and incentivized) to spot obvious anomalies, not low-level structural inconsistencies. AI has made forging identity documents disturbingly easy, rendering traditional methods dangerously inadequate.
Time pressure makes the gap worse. Finance and compliance workflows often involve high volumes and tight SLAs—so “manual review” becomes a sampling exercise, not a forensic process. Even when reviewers are skilled, they are still limited to what a PDF viewer chooses to render. This matters because PDFs are not just “pages.” They are complex container formats that can preserve prior states, hide content behind layers, or present different content depending on how the file is processed.
Digitally signed PDFs create a particularly dangerous illusion of certainty. Research on so‑called “shadow attacks” demonstrates that attackers can prepare PDFs with multiple contents and later reveal hidden content while a signature may still appear valid to a recipient, exploiting the flexibility of the PDF standard and incremental updates. In short: a human may see a valid signature indicator and assume integrity—while the file still contains manipulation logic that defeats surface trust.
This is the core gap that AI-driven PDF forensics targets:
- Surface-level inspection focuses on what you can see in a viewer: visuals, formatting, and whether a file “looks clean.” However, with advanced AI forgery, it becomes increasingly difficult to prove the authenticity of documents using only these methods.
- Structural forensic analysis focuses on what the PDF is: object references, revision chains, metadata coherence, rendering instructions, and cryptographic validity—much of which is invisible to the naked eye.
What AI actually inspects inside a PDF file
A useful way to understand AI-based PDF forensics is to start with the PDF’s anatomy. A PDF is typically organized into a header, a body (objects), a cross-reference structure that enables random access, and a trailer that points to key structures. These components exist so software can parse, render, and update large documents efficiently.
The detail that matters for fraud detection is that PDFs can be updated incrementally: changes are appended to the end of the file, leaving original bytes intact, adding a new cross-reference section and a new trailer that links back to prior states (often using a Prev pointer). This feature is legitimate—it supports fast saves, collaboration, and certain signing workflows—but it also creates forensic “residue” and a larger attack surface.
From there, AI systems can evaluate signals that humans almost never see. The most important categories are below. In the context of ai forgery, attackers may be creating a false document or forged instrument by intentionally manipulating or generating PDF files to deceive public agencies or legal proceedings. The process of creating such documents with AI involves deliberate alteration or fabrication, which can have serious legal implications.
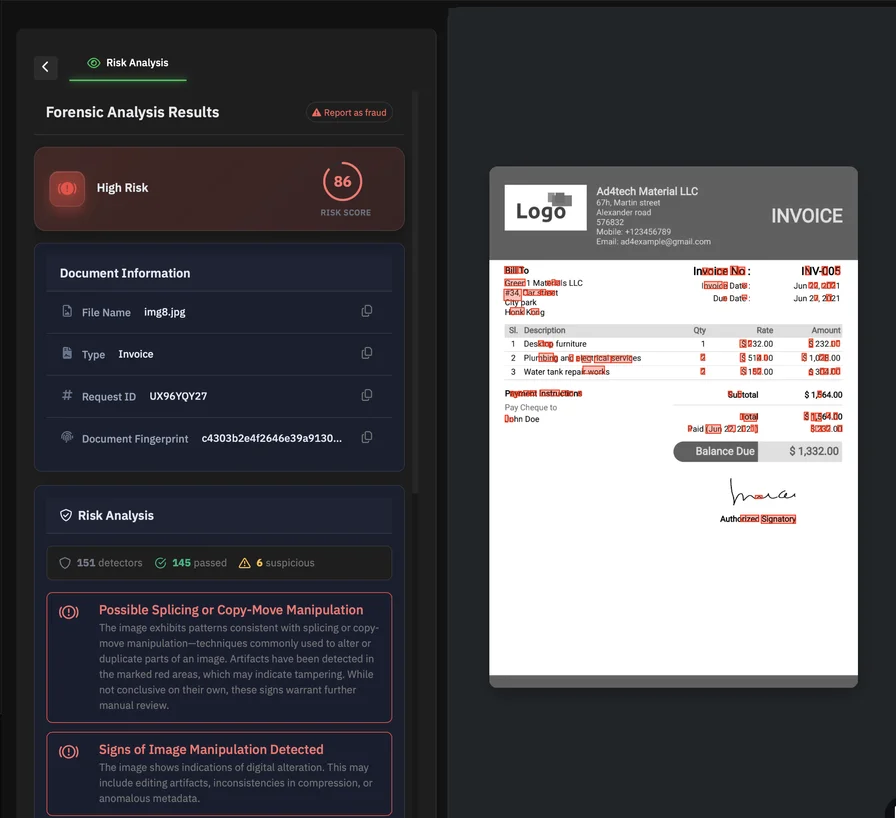
Metadata coherence and provenance signals. PDFs commonly store metadata in a document information dictionary (referenced from the trailer’s Info entry), and may also carry metadata streams (such as XMP). Standard fields include Creator, Producer, CreationDate, and ModDate. AI models can treat metadata as a set of claims and test for internal consistency, plausibility, and alignment with the file’s structural reality. When metadata is easily rewritten using common tooling and libraries (for example, programmatically editing /Producer or other fields), metadata becomes a weak trust anchor on its own—useful as a signal, not as proof.
Timestamp behavior across revisions. Incremental update chains create natural “revision behavior.” When an attacker performs targeted edits, the resulting ModDate, object generation patterns, and update sequencing can look different from a native export flow. Some feature-extraction frameworks explicitly model timestamp irregularities and time deltas as detection features.
Object graph and cross-reference integrity. In a well-formed PDF, the cross-reference structure connects object identifiers to byte offsets; the trailer provides offsets and references needed to locate the current state of the document. AI can detect anomalies such as unexpected object duplication, suspicious object insertions, irregular offsets, or revision patterns inconsistent with the claimed origin (e.g., a “bank statement” that structurally behaves like a graphics-editing export rather than a statement generation system).
Layering, hidden content, and overlays. PDF supports “optional content” (often described as layers), managed through optional content groups and configuration dictionaries. Viewers can selectively show or hide such content, and the PDF standard describes how optional content groups are listed and configured. This matters operationally: content can be present but intentionally suppressed during review, or revealed later, or shown differently across viewers. AI-based analysis can inspect the presence and behavior of optional content structures rather than trusting the rendered output.
Font and text-level anomalies. Many sophisticated forgeries replace only a few characters—an amount too small for the eye to notice. Yet those edits can leave detectable fingerprints: font subset differences, inconsistent glyph maps, unusual encoding patterns, or text objects that do not match the surrounding content’s structure. Feature engineering approaches for PDFs often include font usage and structural parsing counts for this reason.
Compression and image re-encoding artifacts. A large share of business PDFs contain embedded images (scans, screenshots, exported charts, photographed receipts). When an image is manipulated and re-saved, it can exhibit recompression traces. Research on JPEG recompression shows that double-compression is a useful forensic cue and is frequently produced during image manipulation; detection can be used to infer processing history and identify tampered regions. In PDF forensics, AI can use this class of signal to ask: does the “scan” behave like a single capture, or like an edited and re-encoded artifact?
Digital signature validation and cryptographic reality. Checking that a PDF contains a signature field is not the same as validating integrity. Cryptographic signatures are designed to detect unauthorized modification of data (and to authenticate the signer’s identity) when properly generated and verified. In the PDF ecosystem, advanced signature profiles (such as PAdES) build on PDF signatures, but validation requires correct parsing of signature structures, byte ranges, and trusted validation material. And crucially, incremental updates are a normal part of signed-PDF workflows: the PDF reference explicitly notes that once a document has been signed, changes must be saved using incremental updates because altering existing bytes invalidates signatures. That nuance is precisely where attackers try to hide—making true cryptographic validation, structural checks, and “what changed where” analysis essential.
Template cloning patterns across submissions. The fraud problem is rarely one forged document. It is repeated, evolving abuse—often using the same base templates with small edits. National Fraud Database reporting suggests exactly this: recurring templates in circulation, modified with simple edits, sometimes passing verification checks. AI becomes especially valuable here because it can learn “what normal looks like” across thousands of files and flag reused structures, suspicious similarity clusters, and coordinated submission patterns.
While the creation or distribution of synthetic content, such as a false document or forged instrument, is not inherently illegal, it can be used to facilitate crimes such as fraud and extortion.
Basic PDF validation vs forensic-level AI analysis
Traditional PDF checks are necessary—but they tend to answer only one question: “Is this file readable and does it look legitimate?” AI-driven forensics is aimed at a different question: “Is this file consistent with how legitimate documents of this type are normally produced, and is there evidence of manipulation or deceptive construction?” In forensic analysis, establishing the intent behind the creation or alteration of a document, as well as its legal significance, is crucial for proving whether a forgery has occurred. The ability to demonstrate both the deliberate purpose (intent) and the document’s role within the law (legal significance) can determine the outcome of forgery cases.
| Traditional checks | AI-powered forensic analysis |
| Visual review in a PDF viewer | Structural deep analysis of objects, revision chains, and rendering logic |
| Manual spot checks (sampling) | Automated full-document scanning, consistent across files and teams |
| “Signature present” / checkbox validation | Cryptographic validation + interpretation of signed byte ranges and post-signing updates |
| Basic metadata viewing | Cross-field metadata coherence + behavioral verification against structural reality |
| One-off inspection | Pattern recognition across large document volumes, including template reuse detection |
The key operational insight is consistency. Humans are variable. They miss things when tired, rushed, or overloaded. Software is consistent—if you build it to check the right things. That is why fraud guidance increasingly points toward “use AI to catch AI,” specifically because AI can spot imperceptible patterns in how an image or document was created that do not reliably register in human review. In the context of AI forgery, online artists now face a higher burden of proof, as they must provide clear evidence of their work's authenticity in an environment where AI-generated art is widespread.
Where forged PDFs hit hardest and the compounding cost of scale
PDF forgery is not evenly distributed. It clusters where PDFs represent money, access, or liability:
Fintech and lending remain prime targets because bank statements, payslips, and proof-of-address documents can directly influence underwriting decisions. Law enforcement threat assessments explicitly warn that criminals can now craft messages at scale, impersonate individuals, and use AI-enabled techniques to amplify fraud, identity theft, and identity fraud—capabilities that translate into “document-driven” fraud in financial workflows. Criminals use AI and forged documents to deceive and defraud both individuals and organizations, making it critical for companies to implement advanced digital identity verification solutions to protect themselves and their customers.
Insurance is heavily exposed because claims often depend on documentation (invoices, proof of ownership, supporting evidence). Procurement and accounts payable are exposed because invoices and supplier documents are high-trust artifacts that often move quickly through operational pipelines; even a small success rate becomes expensive at volume.
HR and hiring teams face a different, but still material, risk: credential fraud, altered certificates, and fabricated employment or income evidence. Risk bodies focused on remote identity proofing explicitly categorize “false documents” and “forgeries” and note digital techniques (including modern generative approaches) as part of document fraud attacks. Submitting a false form or falsifying any legal document can have serious legal consequences for the person involved, including forgery charges and criminal penalties.
The compounding cost comes from scale. Fraud is operationally opportunistic: once a method works, it is repeated. That is what Cifas is describing when it notes template reuse in circulation with simple edits. At that point, a single gap in manual review is no longer a one-off error—it becomes an intake vulnerability.
Regulatory exposure amplifies the impact. International AML guidance warns that remote or “non-face-to-face” processes can raise risk and that reliability can be undermined by identity theft, identity fraud, and source documents that are easily forged or tampered with; it explicitly associates remote contexts with the possibility of “massive attack frauds.” And supervisory guidance for remote customer onboarding emphasizes governance, pre-implementation assessment, fraud testing (including impersonation risks), and ongoing monitoring—reflecting the expectation that institutions must treat document-driven onboarding as a controlled risk system, not an ad hoc checklist.
Forgery is treated as a serious criminal offense under both state and federal law. For example, under Pennsylvania's new digital forgery law, using AI to produce forged digital likenesses can result in a third-degree felony charge. In California, falsifying documents is considered a serious form of white collar crime that can corrupt public records and interfere with legal processes. A conviction for falsifying documents in California can lead to felony sentencing, including imprisonment, prison time, fines, and long-term consequences. Criminal penalties for forgery charges are severe and can include felony charges, significant fines, and lasting impacts on a person's record and future opportunities. California law treats forgery as a serious offense because it undermines trust in legal and financial systems.
If you have concerns about potential forgery, believe you are a victim of an AI scam, or have been deceived into sending money, contact legal counsel or the appropriate authorities immediately. The FBI has issued warnings about AI-driven scams, and both federal and state agencies are coordinating efforts to protect consumers and organizations from these evolving threats.
In the art market, AI-generated art forgery poses significant risks by producing highly convincing counterfeits and fake provenance records that can deceive even seasoned specialists. This undermines trust, lowers buyers' willingness to pay, and threatens the market value of original works. There is a growing need for AI-powered authentication services to detect art forgeries, creating an 'AI arms race' in the industry. The future of art market verification may rely on a combination of AI technical analysis, traditional connoisseurship, and scientific material analysis, as deep learning algorithms can now analyze brushstrokes and color palettes with up to 98% accuracy. As a result, the cost of verifying art is expected to rise, leading to a crisis of authenticity and impacting both artists and companies operating in the market.
How AI-based PDF forensics works at scale in real workflows
AI-based PDF forensics is best thought of as infrastructure: a standardized decision layer that sits between “a PDF was submitted” and “a business process accepts the claim.” These security strategies are crucial for organizations and companies, as they help protect both the business and its customers from AI-driven identity fraud and document forgery.
Under the hood, modern systems typically combine:
A feature extraction pipeline that parses metadata, structure, and content. Research on PDF analysis (even in adjacent safety domains like malicious document detection) highlights commonly used features such as document size, number of pages, font usage, object streams, metadata timestamps, keyword and object-type presence, and structural patterns. These are not “visual” features. They are file-internal behavioral signals.
An anomaly detection layer that flags deviations from expected structure. PDFs have predictable mechanics: cross-reference sections and trailers, incremental update behavior, optional content structures, and signature constructs. When a file’s internals don’t match its claimed provenance or expected production path, that mismatch becomes a fraud-relevant signal—especially when combined with other anomalies.
A fingerprinting and similarity layer that detects repeated template patterns (including near-duplicates). This matters because fraud actors reuse what works, and defenders need to connect “this looks like the last 200 attempts” even when each file is slightly altered.
An explainable output appropriate for operational teams: a risk score, reason codes (e.g., “non-native object insertion,” “timestamp inconsistency,” “layer-based concealment indicators”), and evidence artifacts that can be stored for audit and dispute handling.
This is where PDFchecker should be positioned: not as a viewer, not as a single-purpose “upload tool,” but as an AI-driven PDF forensics layer that can be integrated via API into onboarding, underwriting, procurement, claims, and compliance workflows—so verification is automated, consistent, and scalable. By acting decisively to implement a multi-layered, multi-factor approach to identity verification, organizations and companies significantly increase the complexity for fraudsters attempting ai forgery. Verified digital identities are widely recognized as the long-term solution for secure identity verification.
In practice, that means building workflows where:
- High-risk documents are automatically routed to enhanced review based on forensic risk scoring.
- Known-good document types have strict structural baselines.
- Emerging fraud patterns (such as new template families) are detected across submissions, not only within a single file.
The key design principle is simple: treat PDFs as executable containers of structure, not as pictures of paper.
The AI arms race and why automation is becoming mandatory
Generative AI is improving. That is not speculative—it is reflected in threat assessments and fraud intelligence that describe rising accessibility, higher realism, and reduced need for specialized skill in producing convincing fakes.
Defenders therefore have to assume two things at once:
First, forgery quality will keep rising, and “visual tells” will keep disappearing. Second, attackers will keep exploiting scale—automating both production and distribution—because remote submission channels reward throughput.
The practical implication is a shift in posture:
- From reactive review to proactive risk scoring (screen everything, escalate only what warrants attention).
- From trusting metadata or signatures at face value to verifying structural and cryptographic reality.
- From isolated human judgment to continuous, adaptive detection that learns from new fraud patterns and template families.
Fake PDFs are increasingly sophisticated. Manual review—no matter how diligent—is no longer a reliable control at scale. Structural analysis is essential, because it targets the parts of the document attackers must manipulate to alter meaning: objects, revisions, layers, resources, images, and signatures.
AI-driven PDF forensics is not just a “better checker.” It is a necessary layer of verification infrastructure for any platform that depends on digital documents as evidence—especially when those documents are used to approve money, access, employment, or legal decisions.
The new frontier: AI-generated threats in document forgery
Artificial intelligence is rapidly reshaping the landscape of document forgery, introducing a new wave of threats that are both sophisticated and accessible. Generative AI tools can now produce fake documents—such as written instruments, passports, and driver’s licenses—that are nearly indistinguishable from genuine ones, even under close inspection. This leap in capability means that anyone with access to these AI-powered platforms can create convincing forgeries without specialized skills or expensive software.
The implications for fraud and security are profound. AI-generated documents are increasingly being used to commit fraud, facilitate identity theft, and enable a range of crimes that exploit trust in digital paperwork. For example, a forged driver’s license or passport created with generative AI can be used to bypass identity checks, open fraudulent accounts, or gain unauthorized access to services and financial resources. The speed and scale at which these fake documents can be produced make it difficult for traditional verification methods to keep up.
In our daily lives, the risk is no longer limited to high-profile scams or targeted attacks. AI-driven document forgery can impact anyone—from individuals seeking immediate financial assistance to organizations processing onboarding or compliance checks. The ability to generate fake credentials, alter sensitive information, or fabricate entire written documents with a few clicks has lowered the barrier for would-be fraudsters and expanded the attack surface for identity-related crimes.
As artificial intelligence continues to evolve, so too does the threat landscape. Organizations must recognize that AI-generated forgeries are not just a theoretical risk—they are an active and growing challenge that demands advanced, AI-powered defenses. Only by leveraging equally sophisticated detection tools can businesses and individuals hope to protect themselves against the new generation of document forgery and the wide-ranging fraud it enables.